

先做个广告:如需代注册ChatGPT或充值 GPT4.0会员(plus),请添加站长微信:gptchongzhi

 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top

来源:高毅资产管理(ID:gyzcgl)
1.为什么大家都如此关注ChatGPT?
相较于其它物种,人类的智慧在于我们是工具创造者。回顾科学史,所有科学家一直在追求:人类有没有可能创造出和我们一样类似的高级智人?AGI(Artificial general intelligence通用人工智能)是计算机发展半个多世纪以来不断追求的“圣杯”。
ChatGPT给大家打开了这个想象空间。
2.ChatGPT能做什么?
读书写字、数字分析、信息提炼、总结知识、教授方法、智库分享、翻译等等,ChatGPT用对话的形式展现了大语言模型在内容整理和摘要方面的突破性进展。每个人都可以通过自己的探索发现新的AI应用场景,以前我们需要100个APP的工作,一个AI机器人就能完成。甚至我们每个人都可以成为AI科学家。

图片来源:chatGPT
3.ChatGPT从哪里来?背后的核心原理是什么?
ChatGPT并不是横空出世。70余年来,整个计算机技术的发展在一定程度上都可以看作对人工智能技术的一次次突破和前进,从早期符号主义、逻辑主义的简单规则设置,到今天大语言模型代表的统计规律胜利,人类在一步步迈向通用人工智能。
20年来人工智能的最大突破就是从堆叠逻辑到统计学,而ChatGPT是过去十年来AI技术积累的集中成果展示。
ChatGPT背后的技术动力源泉就是LLM大语言模型(Large Language Model),LLM背后的核心原理就是统计计算。通过建立一个有上千亿个变量的复杂数学方程来模拟我们大脑中的语言规则,一旦得到方程,每个词都变成了概率,语言就可以被计算出来。相当于我们只要有这个方程就知道这句话该这样说,或者这句话之后表意什么。
举个例子,假如我们让AI做续写 “The best thing about AI is its ability to”,让它给我补充后面的句子该填写什么,这时机器会怎么做呢?它通过海量语料发现前面出现“The best thing about AI is its ability to”之后,出现最高概率的五个词是do、understand、make、predict、learn,它在其中选择概率较高的learn补全了这个句子。本质上所谓的大语言模型就是选出最可能的下一个词。
如果大家用过ChatGPT类的产品,会发现一个很有意思的交互特征,就是它的词是一个一个往外蹦的,不是因为他们做成特殊的交互,是因为机器真的在算,只有算出上一个词,再把这个句子重新带回去,才知道出现最高概率的词是什么,所以它的展现只能是一个词一个词往外蹦,这不是模拟打字的效果,而是它真实的在后台计算。
4.人类大脑的语言规则如此复杂,ChatGPT是怎么得出这套复杂的公式?又是怎么执行完成的?
数据量足够大、计算量足够大,就会产生质变——机器能掌握更接近语言规则的高维度复杂的工程,也就是我们自己都不能言说的方程,诞生了今天这样的效果。这就是ChatGPT背后的大语言模型原理,看结构并不复杂,但每一步工程都需要很多心血和汗水的突破。是一个持续近十年的工程:
2014年Attention机制的提出,它是一种算法;
2017年石破天惊的Transformer结构论文,相当于诞生出有庞大知识库、非常强大能力的大模型,但它的主要问题是不太会与人沟通;
2020年的GPT-3,依靠Transformer机制和海量数据训练,一步一步关键技术解决和迭代的过程,才诞生了今天的大语言模型。

5.为什么是ChatGPT?为什么不是其他产品?
非常关键的一点就是人工反馈的强化学习,也就是RLHF(Reinforcement Learning from Human Feedback)。本质上ChatGPT = GPT-3.5 + RLHF,GPT是其支撑模型,模型背后真正的科技是LLM海量数据统计的涌现效应,而RLHF技术是其效果突围的关键。
LLM和RLHF的关系,LLM就像一个聪明、有知识但不善言辞的孩子,RLHF就是用一系列例子教会他人类日常交流的模式。GPT-3依靠Transformer机制和海量数据训练,实现了对人类知识的初步统计归总;RLHF就是让人来给机器的输出打分,奖励“好话”,惩罚“坏话”,不断驯化AI的说话习惯,即强化学习人类日常交流模式。两层模型堆叠,输出了非常好的ChatGPT产品。
6. ChatGPT能取代人吗?
盈亏同源,ChatGPT大语言模型的核心原理就是“统计+强化”,这决定了它不是真的理解,因为语言不是知识,模仿不是理解,说得像人话并不等于真的明白话的含义。AI是一个抄作业的人,它通过人类浩瀚的语料去抄或者模仿人曾经做过的事,它并不真正明白这件事,只是因为它抄过的东西太多,所以可以抄得非常强大、非常准,抄得非常像人话,但这并不等于它真的理解。
当我们问AI 3+5等于多少,大家以为它用计算器算3+5是多少,其实不是,它是去浩瀚的语料里找哪儿出现过3+5,统计3+5后面基本都是出现8,于是把8贴上了,这意味着它很可能有很多错漏。
这也回答了很多人目前的担忧:AI还不能取代人。因为AI没有人类的常识,它是抄作业,它一本正经,语法很通顺,写得很好,看起来非常专业,除了不对,几乎没缺点。但它还需要持续解决真实性和有效性的问题,这会限制它在很多要求准确率更高的场景下的持续扩展。
7.AI未来会取代人吗?
它现在还难以说是真正的AGI,让机器从“掌握信息”升级为“掌握知识”还需要AI科技的进一步突破,具备逻辑的自主学习和推演能力才是AGI,通往未来,会使用工具的AI将造就新的入口和新的平台,
本次AI最大的想象空间在于其方法论:AGI=DL+RL(深度学习+强化学习),指向了一个曾经只出现在科幻电影中的全能服务机器人。到那一天,我们的生活会发生很大变化。
它现在还难以说是真正的AGI,但我们已经看到它开始深度改变我们的学习和生活。
8.机会在哪里?
数字化的上半场是云,下半场是AI 。参考移动时代,新技术不仅带来了新的独角兽,也让掌握基础设施的巨头享受了新增量,AI对应用和云都是机会。
它现在还难以说是真正的AGI,但我们已经看到它开始深度改变我们的学习和生活。如将大语言模型与机器视觉模型结合能够实现阅图理解、按文生图等新形态应用。多模态AI能综合利用对文字、视觉和语言等的认知能力,更加深入地嵌入我们的生活和工作,拓展出更多的应用场景。未来通过大语言模型,可以降低各类现有模型的落地实施成本,让机器自动完成原本人才能解决的需求适配和功能对接,打通AI to B的最后一公里。
如能帮助人类生成代码,大幅降低程序代码编写的时间:
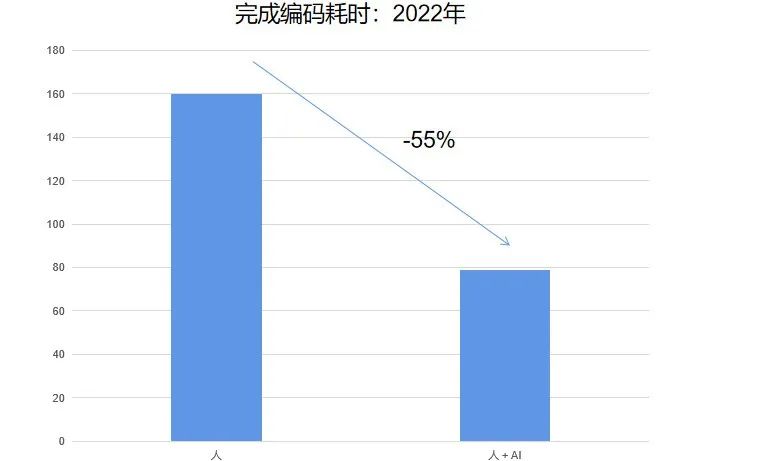 数据来源:ARK Investment : Artificial Intelligence
数据来源:ARK Investment : Artificial Intelligence
大幅降低图片和视频生产的成本:
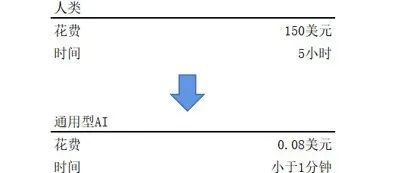
数据来源:ARK Investment : Artificial Intelligence
9.中国的机会在哪里?
我们还处在AIGC(AI Generated Content,人工智能生成内容),发展的早期阶段,行业的探索才刚刚开始。
中国具备完整的AI技术栈,也能有自己的ChatGPT。ChatGPT分为两层,一层是GPT模型,一层是奖励模型。国内在2021年前后基本完成了GPT-3同级别的LLM模型,RLHF是需要时间打磨的人工策略积累,中国有更高的执行效率,客观看待中国ChatGPT第一版的效果,会有差距,但可以追赶。
10.我们要做什么?
乔布斯说过的一段话:What a computer is to me is the most remarkable tool that we have ever come up with. It’s the equivalent of a bicycle for our minds.
也许这一波AI的突破不仅仅是“自行车”,而是“汽车”,会把我们带向更光明的未来。隧道尽头的光已经打在我们身上,接下来要做的可能就是一直向前。
版权声明:部分文章推送时未能与原作者取得联系。若涉及版权问题,敬请原作者联系我们。







{kind=link}
{kind=link}